Вот сценарий, в котором я нахожусь.
У меня достаточно большая таблица, из которой мне нужно запрашивать последние записи.Вот создание основных столбцов для запроса:
CREATE TABLE [dbo].[ChannelValue](
[ID] [bigint] IDENTITY(1,1) NOT NULL,
[UpdateRecord] [bit] NOT NULL,
[VehicleID] [int] NOT NULL,
[UnitID] [int] NOT NULL,
[RecordInsert] [datetime] NOT NULL,
[TimeStamp] [datetime] NOT NULL
) ON [PRIMARY]
GO
Столбец идентификатора является первичным ключом, и для идентификатора транспортного средства и TimeStamp существует некластеризованный индекс
CREATE NONCLUSTERED INDEX [IX_ChannelValue_TimeStamp_VehicleID] ON [dbo].[ChannelValue]
(
[TimeStamp] ASC,
[VehicleID] ASC
)ON [PRIMARY]
GO
Таблица, над которой я работаю, чтобы оптимизировать мой запрос, составляет чуть более 23 миллионов строк и всего лишь в 10 раз превышает размеры, с которыми должен работать запрос.
Мне нужно вернуть самую последнюю строку для каждого идентификатора транспортного средства.
Я просматривал ответы на этот вопрос здесь, в StackOverflow, и я провел немало поисков в Google, и, кажется, есть 3 или 4 распространенных способа сделать это на SQL Server 2005 и выше.
Пока самый быстрый метод, который я нашел, это следующий запрос:
SELECT cv.*
FROM ChannelValue cv
WHERE cv.TimeStamp = (
SELECT
MAX(TimeStamp)
FROM ChannelValue
WHERE ChannelValue.VehicleID = cv.VehicleID
)
При текущем количестве данных в таблице требуется около 6 секунд, что находится в разумных пределах, но собъем данных, которые таблица будет содержать в реальной среде, запрос начинает выполняться слишком медленно.
Глядя на план выполнения, меня беспокоит вопрос о том, какой SQLСервер пытается вернуть строки.
Я не могу опубликовать образ плана выполнения, потому что моя репутация недостаточно высока, но сканирование индекса выполняет синтаксический анализ каждой строки в таблице, что сильно замедляет запрос.
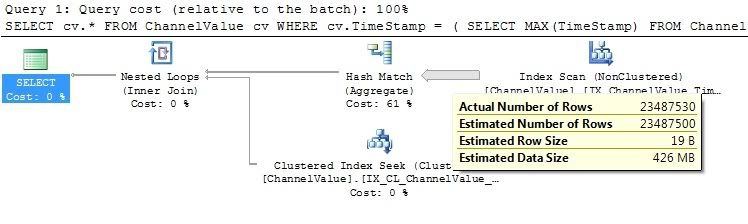
Я пытался переписать запрос несколькими различными методами, в том числе с использованием метода разбиения SQL 2005, например:
WITH cte
AS (
SELECT *,
ROW_NUMBER() OVER(PARTITION BY VehicleID ORDER BY TimeStamp DESC) AS seq
FROM ChannelValue
)
SELECT
VehicleID,
TimeStamp,
Col1
FROM cte
WHERE seq = 1
Но производительность этогозапрос еще хуже на довольно большую величину.
Я пытался реструктурировать запрос, как этот, но скорость результата и план выполнения запроса почти идентичны:
SELECT cv.*
FROM (
SELECT VehicleID
,MAX(TimeStamp) AS [TimeStamp]
FROM ChannelValue
GROUP BY VehicleID
) AS [q]
INNER JOIN ChannelValue cv
ON cv.VehicleID = q.VehicleID
AND cv.TimeStamp = q.TimeStamp
У меня естьмне предоставляется некоторая гибкость в отношении структуры таблиц (хотя и в ограниченной степени), чтобы я мог добавлять в базу данных индексы, индексированные представления и т. д. или даже дополнительные таблицы.
Я был бы очень признателен за любую помощь здесь.
Редактировать Добавлена ссылка на изображение плана выполнения.