Итак, я хотел проверить скорость C ++ против Matlab для решения линейной системы уравнений. Для этого я создаю случайную систему и измеряю время, необходимое для ее решения, используя Eigen в Visual Studio:
#include <Eigen/Core>
#include <Eigen/Dense>
#include <chrono>
using namespace Eigen;
using namespace std;
int main()
{
chrono::steady_clock sc; // create an object of `steady_clock` class
int n;
n = 5000;
MatrixXf m = MatrixXf::Random(n, n);
VectorXf b = VectorXf::Random(n);
auto start = sc.now(); // start timer
VectorXf x = m.lu().solve(b);
auto end = sc.now();
// measure time span between start & end
auto time_span = static_cast<chrono::duration<double>>(end - start);
cout << "Operation took: " << time_span.count() << " seconds !!!";
}
Решение этой системы 5000 x 5000 занимает в среднем 6,4 секунды. То же самое в Matlab занимает 0,9 секунды. Код Matlab выглядит следующим образом:
a = rand(5000); b = rand(5000,1);
tic
x = a\b;
toc
Согласно этой блок-схеме оператора обратной косой черты:
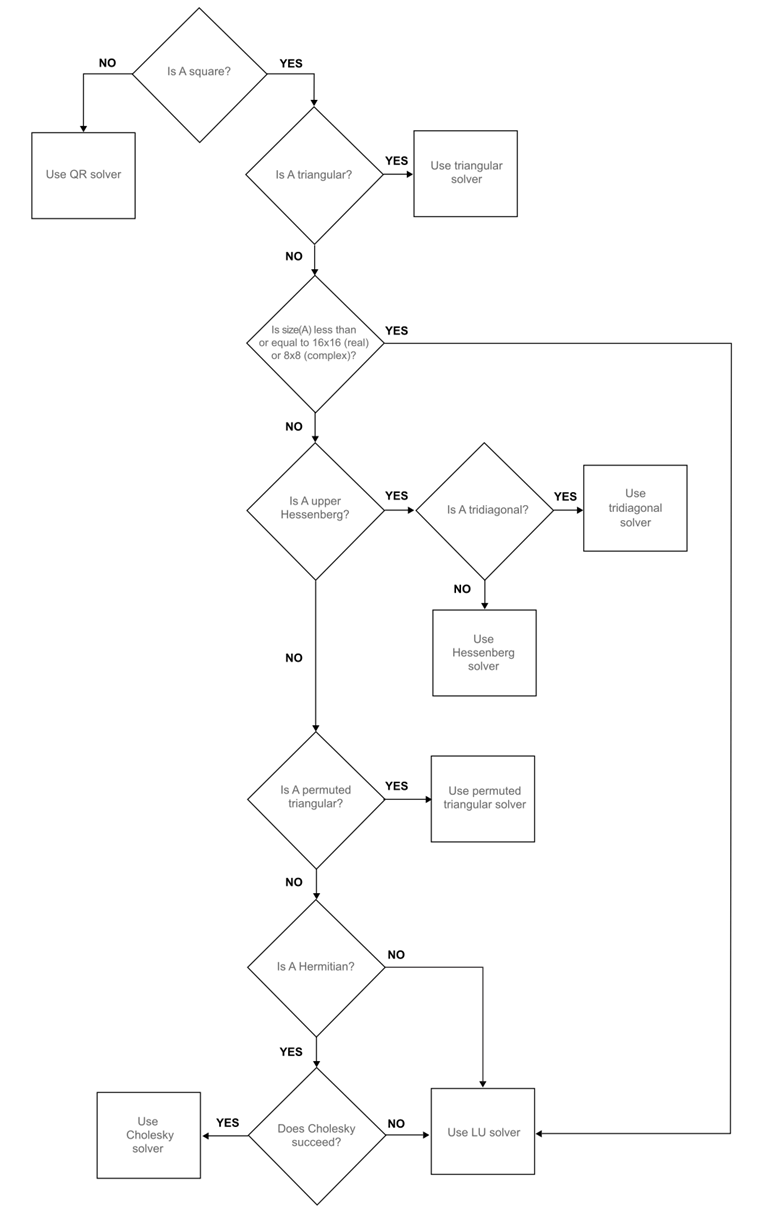
учитывая, что случайная матрица не является треугольной, переставленной треугольной, эрмитовой или верхней Гейзенберга, оператор обратной косой черты в Matlab использует решатель LU, который, как я считаю, тот же, что и используемый в коде C ++, то есть lu().solve
Возможно, что-то мне не хватает, потому что я думал, что C ++ был быстрее.
- Я запускаю его с активным режимом выпуска в Configuration Manager
- Свойства проекта - C / C ++ - Оптимизация - / O2 активен
- Пробовал с использованием расширенных инструкций (SSE и SSE2). SSE фактически сделал это медленнее, а SSE2 почти ничего не изменило.
- Я использую версию Visual Studio для сообщества, если это имеет какое-либо значение