Я немного новичок в этой области и поэтому решил работать с набором данных MNIST.Я в значительной степени адаптировал весь код https://github.com/pytorch/examples/blob/master/mnist/main.py, с одним существенным изменением: загрузка данных.Я не хотел использовать предварительно загруженный набор данных в Torchvision.Поэтому я использовал MNIST в CSV .
Я загрузил данные из файла CSV, унаследовав его от Dataset и сделав новый загрузчик данных.Вот соответствующий код:
mean = 33.318421449829934
sd = 78.56749081851163
# mean = 0.1307
# sd = 0.3081
import numpy as np
from torch.utils.data import Dataset, DataLoader
class dataset(Dataset):
def __init__(self, csv, transform=None):
data = pd.read_csv(csv, header=None)
self.X = np.array(data.iloc[:, 1:]).reshape(-1, 28, 28, 1).astype('float32')
self.Y = np.array(data.iloc[:, 0])
del data
self.transform = transform
def __len__(self):
return len(self.X)
def __getitem__(self, idx):
item = self.X[idx]
label = self.Y[idx]
if self.transform:
item = self.transform(item)
return (item, label)
import torchvision.transforms as transforms
trainData = dataset('mnist_train.csv', transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((mean,), (sd,))
]))
testData = dataset('mnist_test.csv', transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((mean,), (sd,))
]))
train_loader = DataLoader(dataset=trainData,
batch_size=10,
shuffle=True,
)
test_loader = DataLoader(dataset=testData,
batch_size=10,
shuffle=True,
)
Однако этот код дает мне абсолютно странный график ошибок обучения, который вы видите на рисунке, и окончательную ошибку проверки в 11%, поскольку он классифицирует все как «7».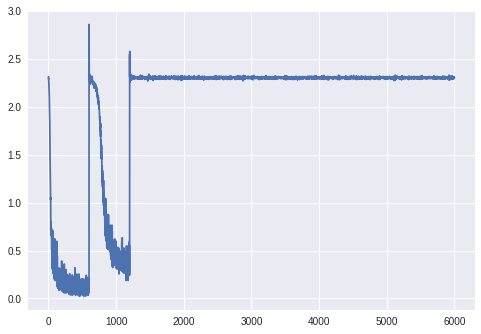
Мне удалось отследить проблему до того, как я нормализую данные, и если я использую значения, приведенные в коде примера (0,1307 и 0,3081) для преобразований. Нормализуйте вместе с чтением данных какнаберите 'uint8', он работает отлично.Обратите внимание, что существует очень минимальная разница в данных , которая предоставляется в этих двух случаях.Нормализация на 0,1307 и 0,3081 для значений от 0 до 1 имеет тот же эффект, что и нормализация на 33,31 и 78,56 для значений от 0 до 255. Значения даже в основном одинаковы (черный пиксель соответствует -0,4241 в первом случае и -0,4242во втором).
Если вы хотели бы видеть Блокнот IPython, где эта проблема видна отчетливо, пожалуйста, проверьте https://colab.research.google.com/drive/1W1qx7IADpnn5e5w97IcxVvmZAaMK9vL3
Я не могу понять, что вызвало такой огромныйРазница в поведении внутри этих двух немного разных способов загрузки данных.Любая помощь будет высоко ценится.