Индекс GiST является обобщением индекса B-дерева.
В неконечном блоке индекса B-дерева две последовательные записи индекса определяют границу дляиндексированные значения в поддереве в месте назначения указателя между этими индексными записями:
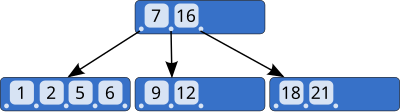
Другими словами, каждый указатель на следующий более низкий уровень помечается интервалом, который содержит всезначения в поддереве.
Это работает только для типов данных с общим порядком .
Индекс GiST расширяет эту концепцию.Каждая запись в неконечном узле имеет условие , которому должно удовлетворять поддерево в этой записи индекса.
При сканировании индекса GiST я ищу на странице индекса все записи, которые могутсодержат значения, соответствующие моим условиям поиска.Поскольку нет полного упорядочения, возможно (но, конечно, нежелательно), что условия как-то «перекрываются», так что что-то, что я ищу, может иметь совпадения в более чем одной из записей.В этом случае мне нужно спуститься во все указанные поддеревья, но я могу пропустить те, в которых условие записи гарантирует, что поддерево не может содержать записи, соответствующие моему условию поиска.
Это немного абстрактно, поэтому давайте рассмотримэто пример.
Одним из классических примеров индекса GiST является индекс R-tree , своего рода географический индекс, подобный тому, который используется PostGIS:

Здесь условием записи индекса является ограничивающий прямоугольник , который содержит ограничивающие прямоугольники всех геометрий, содержащихся в поддереве входного указателя.Поэтому при поиске геометрии я беру ее ограничительную рамку и вижу, какая из записей индекса на странице содержит эту ограничивающую рамку.Это поддеревья, в которые мне нужно спуститься.
В этом примере видно, что индекс GiST может составлять с потерями , то есть он дает мне необходимо , но не достаточное условие, если я обнаружил попадание.Листовые записи, найденные при сканировании индекса GiST, всегда должны быть перепроверены, если фактическая запись таблицы также удовлетворяет условию (не каждая геометрия является прямоугольником).Вот почему сканирование индекса GiST - это всегда сканирование индекса растрового изображения в PostgreSQL.
Все это звучит красиво и просто.Самая сложная часть хорошего индекса GiST - это алгоритм picksplit , который определяет при разбиении страницы индекса, какая из записей индекса входит в какую из двух новых страниц индекса.Чем лучше это работает, тем эффективнее будет индекс.
Итак, вы видите, что индекс GiST во многом «похож на» индекс B-дерева.Вы можете видеть индекс B-дерева как оптимизированный особый случай индекса GiST (см. Модуль btree-gist contrib).
Это позволяет мне ответить на ваши вопросы:
Листовой узел GiST также содержит базовые данные и информацию о том, где хранится кортеж кучи
Это верно.
Листья GiST могут содержать или не содержатьвсе данные строки в его ключах
Конечно, запись индекса не содержит всю строку.Но я думаю, что вы имеете в виду правильные вещи.Условие в листе GiST может быть шире, чем фактический объект в таблице, например, ограничивающий прямоугольник больше, чем геометрия.
, если я могу сохранить одну часть данных таблицы в однойлистовой узел и другая часть в другом листовом узле и заставить их указывать на один кортеж кучи, возможно ли это?Это сделает соотношение между кортежем индекса GiST и кортежем кучи много к одному.
Это неправильно.Даже если значение может удовлетворять нескольким записям на индексной странице GiST, оно содержится только в одном из поддеревьев, и только одна конечная страница страницы указывает на любую данную строку таблицы.Это отношение один-к-одному, как в индексе B-дерева.