У меня есть миллионы записей, каждая из которых имеет целое число (p) и матрицу значений X * 3.Для каждой записи цель состоит в том, чтобы найти строку из матрицы по критериям выбора (см. Операторы if в коде).
Я довольно новичок в Python и пытаюсь использовать векторизацию в Pandasиспользуя параллельные вычисления вместо циклов.Я написал программу в двух версиях, одна с Pandas + Numpy, а другая с простыми циклами.
Мне сказали, что использование векторизации и операций с массивами Numpy быстрее, чем циклы.Но пока, версия цикла примерно в 10 раз быстрее: 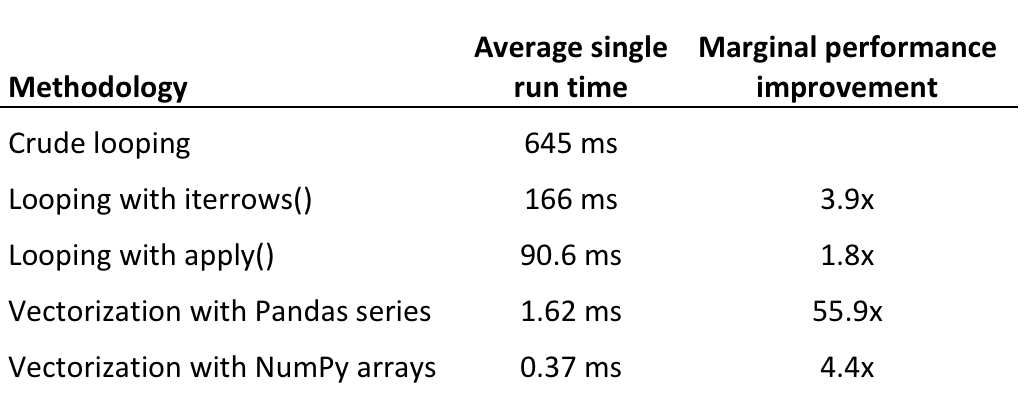
Вот программа:
import numpy as np
import pandas as pd
import time
d = {
'values': [np.array([[1400,1400,1800000],[1500,1505,4800000],[1300,1305,5000]]), np.array([[800,900,80000],[1400,1420,50000],[1250,1300,60000]]), np.array([[1700,1750,5000000],[1900,1950,5000000],[1600,1600,3000000]]), np.array([])],
'p': [1300, 1350, 1800, 1400]
}
# The Pandas+Numpy version
def selection_numpy(row):
try:
# Select rows where col[0] >= p
c1 = row['values'][row['values'][:,0] >= row['p']]
# Select rows where col[2] > 1000000
c2 = c1[c1[:,2]>1000000]
# Sort by col[0] and return the lowest row
return c2[c2[:,0].argsort()][0]
except:
pass
start = time.time()
df = pd.DataFrame(d)
df['result'] = df.apply(selection_numpy, axis=1)
# print(df.head())
print(time.time()-start)
# The loop version:
def selection_loop(values, p):
lowest_num = 9999999999
lowest_item = None
# Iterate through each row in the matrix and replace lowest_item if it's lower than the previous one
for item in values:
if item[0] >= p and item[2] > 1000000 and item[0] < lowest_num:
lowest_num = item[0]
lowest_item = item
return lowest_item
start = time.time()
d['result'] = []
for i in range(0, 4):
result = selection_loop(d['values'][i], d['p'][i])
d['result'].append(result)
# print(d['result'])
print(time.time()-start)
Обе дают одинаковые значения результата, но версия цикла на несколько быстрее (для фактического набора данных миллионов записей, а не для 4 примеров записей.
Я предполагаю, что существует простое и элегантное решение для поиска нужной строки для каждой записи, которая использует векторизацию и является самой быстрой.Не уверен, почему функция, использующая массивы Numpy, такая медленная, но я ценю любые рекомендации.