Ваша формула для similarity вычисляет 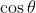 между векторами
между векторами (300,25) и (150,23), или другими словами, измеряет косинус угла между ними.Если вы посмотрите на следующий график, между двумя векторами нет большого угла.Фактически,  градусов, что мало чем отличается от
градусов, что мало чем отличается от 0 градусов, где cos имеет наибольшее значение 1.
Метрика, которую вы здесь используете, должна зависеть от вашего определения сходства.Тривиальная метрика, которую вы можете использовать, - это евклидово расстояние между двумя точками.
Евклидово расстояние между этими двумя точками равно d = 150.01.Например, между (300, 25) и (280,23) есть d = 20.09, что дает представление о том, насколько они разделены в 2D-плоскости.