Я создал фрейм данных со списком компаний и назначил каждой компании несколько ключевых слов (отныне: теги). Фрейм данных выглядит следующим образом:
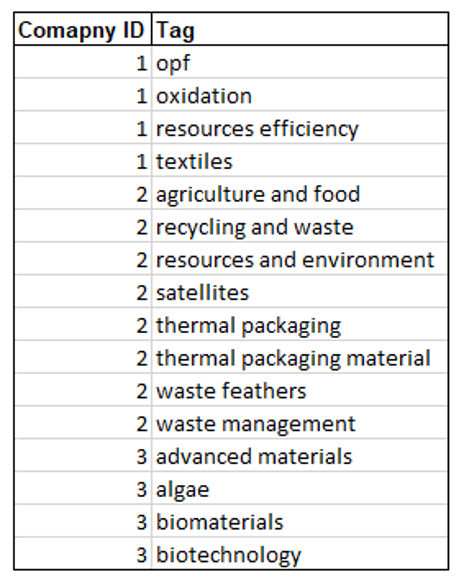
В первом столбце «Идентификатор компании» указан идентификатор компании: уникальный идентификатор для каждой компании. В столбце «Теги» есть теги, связанные с каждой компанией. Например, компания с идентификатором 1 имеет следующие теги: opf, окисление, эффективность использования ресурсов, текстиль. Как правило, теги описывают технологию компании и ее приложения.
На сегодняшний день в фрейме данных насчитывается 1000 компаний и 15.000 тегов.
Я заполнил этот фрейм вручную. По сути, для каждой компании я просматривал ее веб-сайт, искал ключевые слова для использования в качестве тегов и добавил их в свой фрейм данных. Несмотря на то, что этот подход довольно точный, он требует много времени. Мне нужно повторить эту процедуру, чтобы добавить новые компании в мой фрейм данных. Я хочу автоматизировать его.
Моя идея заключается в следующем:
Открыть веб-сайт новой компании - не в пределах 1000 в моем исходном фрейме данных - с помощью селенового веб-драйвера(через Python);
Возьмите весь доступный текст на домашней странице и на других страницах веб-сайта и объедините весь собранный текст в строку (с этого момента мы будем называть эту строку:string _).
Затем я зациклю каждый из 15.000 тегов, уже находящихся в моем фрейме данных, в string_. Если тег находится там, я его сохраню и оставлю в другом месте. Я откажусь от него.
У этого подхода есть существенный недостаток: как я могу обучить свой код и найти новыйключевые слова, которых еще нет среди существующих 15.000 тегов в моем фрейме данных? В то же время, как я могу научить код выбирать только подходящие ключевые слова, которые описывают технологию и ее приложения?
Я потеряю все ключевые слова на сайте, которых нет в моем текущем фрейме данных, с 15.000 тегами. Незначительное решение для этого состоит в том, чтобы включить все синонимы моих тегов (что-то вроде это ). Для меня этого недостаточно.
Плюс, я знаю, что есть некоторые библиотеки Python, которые извлекают ключевые слова из текста, но string_ - это не структурированный текст, а просто часть текста, объединенная вместе. Я пытался это , но код извлекал случайные слова, такие как "О нас", "Facebook", "Свяжитесь с нами" и т. Д.
Не могли бы вы порекомендовать, какой подход вы бы приняли в порядкеЧтобы решить эту проблему?
В конце дня я хочу написать код, который может извлекать теги из 15 000 ключевых слов, которые у меня уже есть в моем фрейме данных, и новые, которые не включены.