Ключевые характеристики OLAP:
- поворот
- нарезка
- нарезка
- сверление
А Redshift может сделать это.
Его архитектура предназначена для решения OLAP и BI задач. См. amazon-redshift-developer-guide
Amazon Redshift специально разработан для приложений онлайн-аналитики c (OLAP) и бизнес-аналитики (BI), которые требуют сложных запросов. против больших наборов данных. Поскольку он отвечает совершенно другим требованиям, специализированная схема хранения данных и механизм выполнения запросов, которые использует Amazon Redshift, полностью отличаются от реализации PostgreSQL. Например, когда приложения обработки онлайновых транзакций (OLTP) обычно хранят данные в строках, Amazon Redshift хранит данные в столбцах, используя специализированные кодировки сжатия данных для оптимального использования памяти и дискового ввода-вывода. Некоторые PostgreSQL функции, которые подходят для мелкомасштабной обработки OLTP, такие как вторичные индексы и эффективные однострочные операции с данными, были упущены для повышения производительности.
Но грань между терминами очень гладко.
Как сказала Диана Шили :
Прекратить злоупотреблять OLTP как OLAP
Между OLTP существует большая путаница на рынке и OLAP, и из-за высокой цены коммерческих OLAP стартапы и разработчики с ограниченным бюджетом стали злоупотреблять базой данных OLTP как базой данных OLAP. Злоупотребление подразделяется на две категории:
- Часто мультисегментная MySQL база данных со сценариями прикладного уровня для выполнения анализа исторических данных событий. Хотя эта настройка чрезвычайно распространена, это один из наименее продуктивных способов подойти к аналитике. MySQL не оптимизирован для чтения больших диапазонов данных, и его поддержка аналитических функций c слабая. Поскольку существует несколько альтернатив, избегайте этого «недорогого» решения, потому что в конечном итоге вы будете расплачиваться в других местах.
- Использование PostgreSQL в качестве уровня OLAP. Это более законный выбор, чем приведенный выше, для запуска аналитической платформы из-за пользовательских функций Postgres solid analyti c (UDF). Кроме того, благодаря расширению магазина c, PostgreSQL можно превратить в столбчатую базу данных, что делает его доступной альтернативой коммерческим OLAP.
Наконец, если вы планируете перейти от OLTP злоупотребляя как OLAP для «настоящих» OLAP, таких как Redshift, я советую вам научиться использовать COPY Command Redshift, чтобы вы могли начать видеть свои данные внутри Redshift.
Что касается Ваши вопросы:
Как это возможно?
Это возможно благодаря архитектуре Redshift (база данных столбцов) и аналитическим функциям, таким как:
Как это будет работать?
См. Система и архитектура O verview для подробного объяснения архитектуры системы хранилища данных Amazon Redshift.
(некоторые ссылки уже упоминались ранее в этом посте)
Основная концепция?
Я что-то упустил?
Я бы посоветовал больше полагаться на технические детали конкретного c решения, а не на маркетинговые условия. В конце концов, практические задачи решаются не именами или маркетингом программного обеспечения, а его реальной функциональностью.
Что действительно важно в ландшафте БД - это рассмотреть две теоремы:
теорема CAP
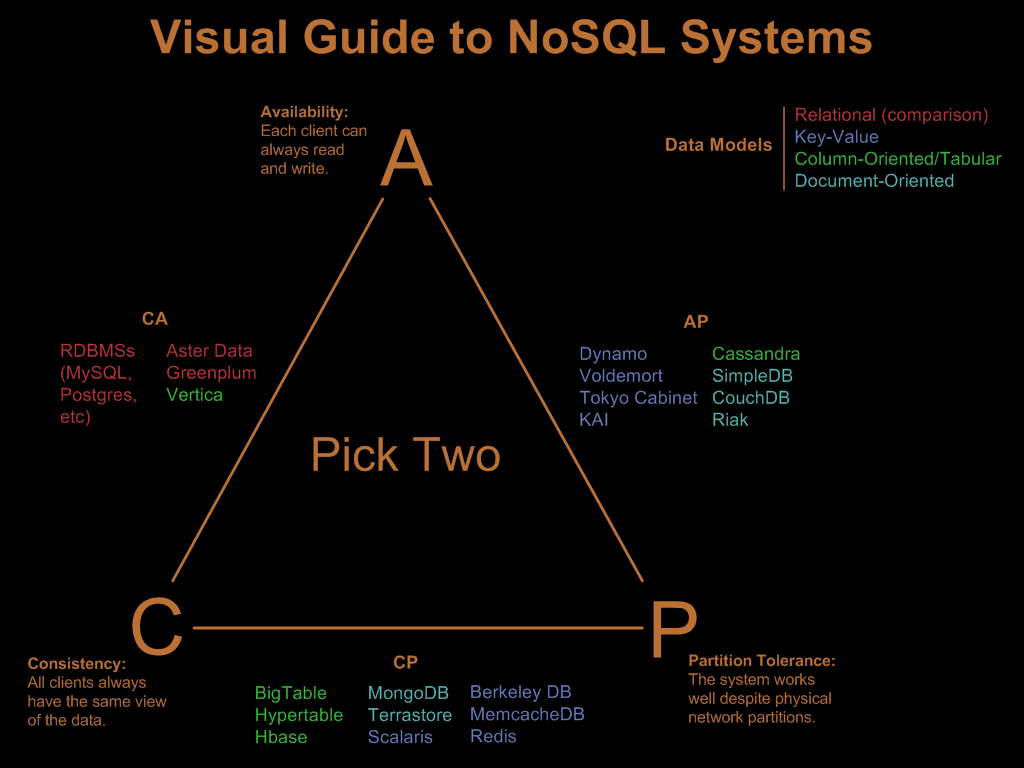
Согласно Iron triangle теоремы CAP Вы можете выбрать две точки из трех компонентов архитектуры БД: * согласованность * доступность * постоянство
P IE теорема
Рик Хулихан из Амазонки выступил с речью о выборе архетектуры БД . В дополнение к теореме CAP он также представил P IE теорему :
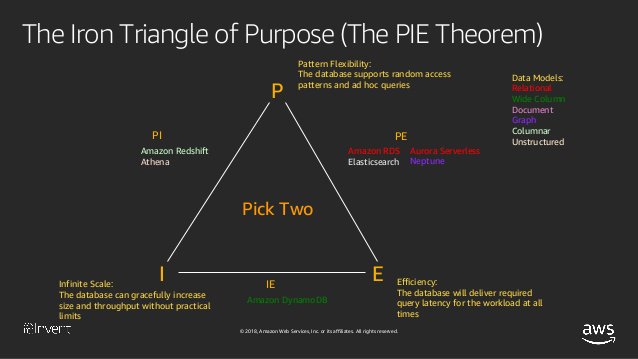
теорему P IE утверждает что вы можете выбрать две из трех желаемых функций в системе данных:
Гибкость шаблона
Эффективность
Бесконечная шкала
И Redshift включено PI измерение PIE triangle
Структура данных
Как я понимаю, кубы OLAP представляют собой особую структуру данных, которая существует в базах данных OLAP. Может быть, он имеет в виду заданные c заранее вычисленные комбинации измерений и фактов, хранящиеся в OLTP-ориентированной базе данных, такой как Cassandra?
Обе OLAP структуры агрегированных данных и Redshift Стили распространения преследовали одну цель: сделать запросы быстрее. БД столбцов, распределение, параллельные запросы и другие функции хороши для аналитических задач.
UPD
В комментариях вы спрашивали, может ли Cassandra работать как OLAP служба. Cassandra и S3 могут использоваться в качестве хранилища для предварительно рассчитанных агрегированных данных измерений.