В принципе, у меня есть набор данных (4 столбца), соответствующих различным результатам экспериментов. Первый, второй и третий столбцы - это x, y и p; где p представляет вероятность P(x, y). Последний столбец - это ошибка p.
Теперь я хочу найти
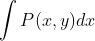
или
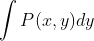
То есть, я хотел бы выполнить символьную c интеграцию над моими данными, так как я хотел бы отобразить его результат.
Некоторые из моих данных:
x y p ep
0 2.967330 2549.603175 1.0 1.00000
1 2.987216 2549.603175 0.0 0.00000
2 3.007102 2549.603175 0.0 0.00000
3 3.026989 2549.603175 3.0 1.73205
4 3.046875 2549.603175 0.0 0.00000
5 3.066761 2549.603175 4.0 2.00000
6 3.086648 2549.603175 1.0 1.00000
8 3.126420 2549.603175 10.0 3.16228
9 3.146307 2549.603175 24.0 4.89898
10 3.166193 2549.603175 35.0 5.91608
11 3.186080 2549.603175 71.0 8.42615
12 3.205966 2549.603175 118.0 10.86280
13 3.225852 2549.603175 188.0 13.71130
14 3.245739 2549.603175 337.0 18.35760
15 3.265625 2549.603175 475.0 21.79450
16 3.285511 2549.603175 706.0 26.57070
17 3.305398 2549.603175 1093.0 33.06060
18 3.325284 2549.603175 1536.0 39.19180
19 3.345170 2549.603175 2239.0 47.31810
По оси x данные находятся на одинаковом расстоянии примерно -0.01988637.
В книге Д. Зиновьева «Python Companion to Data Science» говорится, что «частичные суммы являются приблизительным эквивалентом неотъемлемую". Я хотел бы использовать этот метод частичных сумм, но не знаю, как это сделать.
Заранее спасибо.
С уважением.