Мне трудно из этой исследовательской работы определить, как именно я могу воспроизвести алгоритм стандартного векторного квантования для определения языка неопознанного речевого ввода на основе обучающего набора данных. Вот некоторая основная информация:
Абстрактная информация
Распознавание языка (например, японский, английский, немецкий и т. Д.) С использованием акустических функций является важной, но трудной проблемой для современной речи
технология. ... База речевых данных, используемая в этой статье, содержит 20 языков: 16
приговоры, вынесенные дважды 4 мужчинами и 4 женщинами. Продолжительность каждого
предложение составляет около 8 секунд. Первый алгоритм основан на стандарте
Метод векторного квантования (VQ). Каждый язык характеризуется
по собственной кодовой книге VQ, 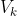 .
.
Алгоритмы распознавания
Первый алгоритм основан на стандартной методике векторного квантования (VQ). Каждый язык, k, характеризуется своей собственной кодовой книгой VQ, . На этапе распознавания входная речь квантуется с помощью и вычисляется накопленное искажение квантования, d_k. Язык, который в качестве минимального искажения признается. При расчете искажения VQ применяются несколько мер спектрального искажения LPC ... в этом случае WLR - взвешенное наименьшее отношение - расстояние: http://tinyurl.com/yc52gcl.
Стандартный алгоритм VQ:
Кодовая книга альтернативный текст http://tinyurl.com/y8csx6e, для каждого языка генерируется с использованием предложений обучения. Накопленное расстояние для входного вектора в предложении, 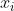 , определяется как: альтернативный текст http://tinyurl.com/ybynjc2
, определяется как: альтернативный текст http://tinyurl.com/ybynjc2
Расстояние d может быть любым расстоянием, которое соответствует акустическим характеристикам, и оно должно совпадать с расстоянием, используемым для генерации кодовой книги. Каждый язык характеризуется своей кодовой книгой VQ .
У меня вопрос, как именно я это делаю? У меня есть набор из 50 предложений на английском языке. В MATLAB я могу легко рассчитать WLR для любого заданного сигнала. Но как мне сформулировать кодовую книгу, поскольку я должен использовать WLR для «генерации кодовой книги» для английского языка. Мне также любопытно, как сравнить кодовую книгу VQ размера 16 (который был признан лучшим размером) с данным входным сигналом. Если бы кто-нибудь мог помочь мне раздать эту бумагу, я был бы очень признателен.
Спасибо!