Я пытаюсь заставить следующий запрос выполняться с разумной производительностью:
UPDATE order_item_imprint SET item_new_id = oi.item_new_id
FROM order_item oi
INNER JOIN order_item_imprint oii ON oi.item_number = oii.item_id
В настоящее время оно не завершается в течение 8 дней, поэтому мы его убили. Объяснение запроса выглядит следующим образом:
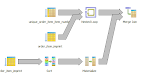
Merge Join (cost=59038021.60..33137238641.84 rows=1432184234121 width=1392)
Merge Cond: ((oi.item_number)::text = (oii.item_id)::text)
-> Nested Loop (cost=0.00..10995925524.15 rows=309949417305 width=1398)
-> Index Scan using unique_order_item_item_number on order_item oi (cost=0.00..608773.05 rows=258995 width=14)
-> Seq Scan on order_item_imprint (cost=0.00..30486.39 rows=1196739 width=1384)
-> Materialize (cost=184026.24..198985.48 rows=1196739 width=6)
-> Sort (cost=184026.24..187018.09 rows=1196739 width=6)
Sort Key: oii.item_id
-> Seq Scan on order_item_imprint oii (cost=0.00..30486.39 rows=1196739 width=6)
У меня есть индексы в обеих таблицах, и я убедился, что сравниваемые поля имеют одинаковый тип и размер. Сейчас я пытаюсь изменить конфигурацию сервера postgresql, чтобы, надеюсь, помочь, но я не уверен, что это поможет.
Размер таблицы order_item_imprint составляет около 1,1 миллиона, а объем дискового пространства - 145 МБ, а таблицы order_item - примерно в 3 раза больше.
Основная цель заключается в том, чтобы мне нужно было выполнить это вместе с несколькими другими запросами в течение нескольких часов обслуживания.
Автоматический вакуум и анализ выполнялись до плана выполнения.