Я пытаюсь запрограммировать приложение для Mac, чтобы оно запрашивало высокопроизводительный вычислительный кластер о его работах по вычислениям и работе в очереди. Цель состоит в том, чтобы иметь возможность отслеживать отправленные задания, если они все еще находятся в очереди и ожидают выполнения или если они выполняются и на каком узле или хосте в кластере.
На стороне графического интерфейса я хотел бы иметь возможность отображать NSTableView, показывающий все отправленные задания и, в качестве альтернативы, второй вариант, чтобы увидеть все узлы в кластере, сколько и какие задания выполняются на каждом узле.
Сами объекты модели сделать не так сложно, меня больше всего беспокоит жизненный цикл и отношения владения между хостом и объектами задания. Это должно быть хорошо продумано, иначе я столкнусь с проблемами управления памятью.
Обратите внимание, что я хотел бы запрограммировать его без использования CoreData, если это возможно.
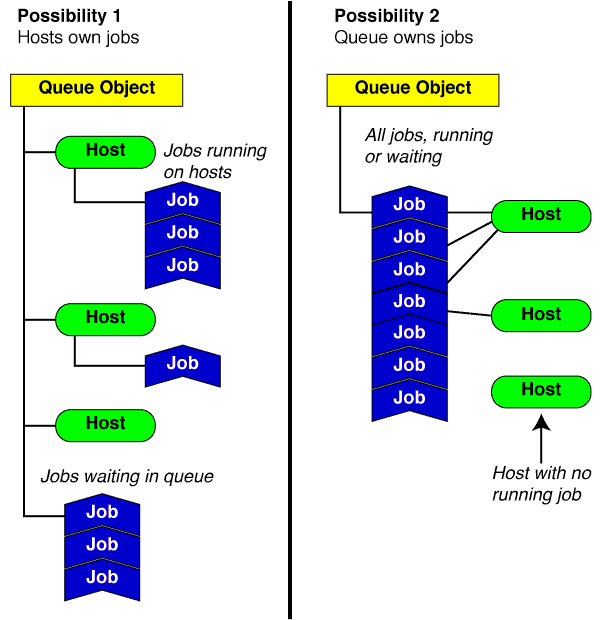
1. Возможность
Желтый объект очереди является корневым объектом моего графа объектов и владеет всеми объектами хоста (имеет NSArray пользовательских объектов хоста). Каждый хост-объект владеет всеми объектами задания, которые выполняются на этом хосте (также имея NSArray пользовательских объектов задания). Я думаю, что у этого подхода есть две основные проблемы:
- где хранятся все объекты заданий, которые все еще находятся в очереди и еще не запущены на хосте. Им не хватает родительского хоста.
- Как реализовать
NSTableView, содержащий все объекты заданий?
2. Возможность
Желтый корневой объект содержит прямые ссылки на все объекты заданий, храня их в NSArray. Каждое задание имеет переменную экземпляра, сохраняющую хост-объект. Опять вот некоторые проблемы
- У меня также были бы узлы в модели, которые в настоящее время не используются, поэтому в настоящее время на них не выполняется никакая работа.
- Как реализовать источник данных для
NSTableView, показывающего все хосты.
- Как убедиться, что нет дублирующих хост-объектов, чтобы каждый хост в кластере был представлен только одним хост-объектом.
Мои вопросы:
1. Какая из двух возможностей имеет больше смысла? Есть ли альтернативы?
2. Будет ли лучше реализовать это с CoreData?
3. Как управлять жизненным циклом объекта, чтобы не было циклов сохранения или висячих указателей.
Спасибо