У меня есть следующий текст из академического курса, который я недавно изучал, о прохождении по порядку (они также называют это блин) из двоичного дерева (не BST):
Обход дерева обхода
Нарисуйте линию вокруг
дерево. Начните слева от корня,
и обойти снаружи дерева,
в конечном итоге справа от корня.
Оставайтесь как можно ближе к дереву,
но не пересекать дерево. (Думать о
дерево - его ветви и узлы - как
твердый барьер.) Порядок
узлы - это порядок, в котором эта строка
проходит под ними. Если ты
не уверены, когда вы идете «под»
узел, помните, что узел «к
слева »всегда на первом месте.
Вот пример (немного другое дерево снизу)
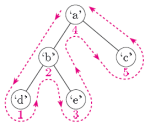
Однако, когда я выполняю поиск в Google, я получаю противоречивое определение. Например, пример Википедии :

Последовательность обхода в порядке: A, B, C,
D, E, F, G, H, я
(левый ребенок, корневой узел, правый узел)
Но согласно (моему пониманию) определению № 1, это должно быть
A, B, D, C, E, F, G, I, H
Может ли кто-нибудь уточнить, какое определение является правильным? Они оба могут описывать разные методы обхода, но могут использовать одно и то же имя. У меня проблемы с верой в то, что рецензируемый академический текст неверен, но не уверен.