Если вы хотите найти один скаляр в массиве, вы можете использовать подпрограмму List :: Util * first.Он останавливается, как только узнает ответ.Я не ожидаю, что это будет быстрее, чем поиск хеша , если у вас уже есть хеш , но если вы подумаете о создании хеша и наличии его в памяти, вам будет удобнее просто выполнить поискмассив, который у вас уже есть.
Что касается умений оператора Smart-Match, если вы хотите увидеть, насколько он умный, протестируйте его.:)
Есть как минимум три случая, которые вы хотите изучить.В худшем случае каждый элемент, который вы хотите найти, находится в конце.В лучшем случае каждый элемент, который вы хотите найти, находится в начале.Вероятный случай состоит в том, что элементы, которые вы хотите найти, в среднем находятся в середине.
Теперь, прежде чем я начну этот тест, я ожидаю, что если интеллектуальное совпадение может замкнуть накоротко (и может; его документированов perlsyn ), что лучшие времена остаются неизменными, несмотря на размер массива, в то время как другие становятся все хуже.Если он не может замкнуть накоротко и должен сканировать весь массив каждый раз, во времени не должно быть различий, потому что каждый случай включает в себя одинаковый объем работы.
Вот эталонный тест:
#!perl
use 5.12.2;
use strict;
use warnings;
use Benchmark qw(cmpthese);
my @hits = qw(A B C);
my @base = qw(one two three four five six) x ( $ARGV[0] || 1 );
my @at_end = ( @base, @hits );
my @at_beginning = ( @hits, @base );
my @in_middle = @base;
splice @in_middle, int( @in_middle / 2 ), 0, @hits;
my @random = @base;
foreach my $item ( @hits ) {
my $index = int rand @random;
splice @random, $index, 0, $item;
}
sub count {
my( $hits, $candidates ) = @_;
my $count;
foreach ( @$hits ) { when( $candidates ) { $count++ } }
$count;
}
cmpthese(-5, {
hits_beginning => sub { my $count = count( \@hits, \@at_beginning ) },
hits_end => sub { my $count = count( \@hits, \@at_end ) },
hits_middle => sub { my $count = count( \@hits, \@in_middle ) },
hits_random => sub { my $count = count( \@hits, \@random ) },
control => sub { my $count = count( [], [] ) },
}
);
Вот как это делали разные части.Обратите внимание, что это логарифмический график на обеих осях, поэтому наклоны линий врезания не так близки, как они выглядят:
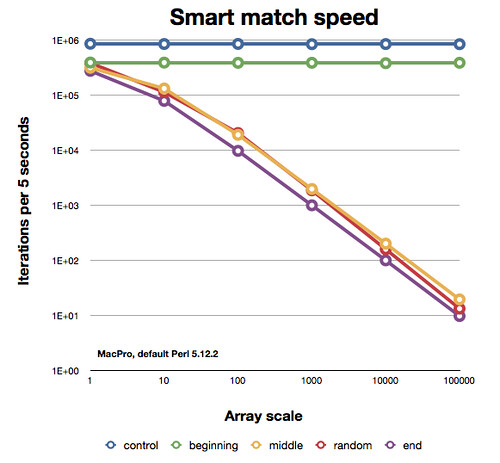
Итак, это выглядит как умное совпадениеОператор немного умен, но это не очень помогает, потому что вам все равно придется сканировать весь массив.Вы, вероятно, не знаете заранее, где вы найдете свои элементы.Я ожидаю, что хеш будет работать так же, как в умном сопоставлении в лучшем случае, даже если вам придется отдать ему немного памяти.
Хорошо, умное совпадение, будучи умным раз два, отлично, нореальный вопрос «Должен ли я использовать это?».Альтернатива - поиск по хешу, и меня беспокоит, что я не рассмотрел этот случай.
Как и в случае с любым другим тестом, я начинаю думать о том, какими могут быть результаты, прежде чем я их на самом деле протестирую.Я ожидаю, что если у меня уже есть хеш, поиск значения будет молниеносным.Этот случай не проблема.Меня больше интересует случай, когда у меня еще нет хеша.Как быстро я могу сделать хеш и найти ключ?Я ожидаю, что это не так хорошо, но все же лучше, чем наихудшее умное совпадение?
Прежде чем вы увидите эталон, тем не менее, помните, что почти никогда не хватает информации о том, какую технику вы должны использовать, простоглядя на цифры.Контекст проблемы выбирает лучшую технику, а не самый быстрый, неконтекстный микропроцессор.Рассмотрим пару случаев, в которых были бы выбраны разные методы:
- У вас есть один массив, который вы будете искать повторно
- Вы всегда получаете новый массив, который вам нужно искать только один раз
- Вы получаете очень большие массивы, но имеете ограниченную память
Теперь, помня об этом, я добавляю к своей предыдущей программе:
my %old_hash = map {$_,1} @in_middle;
cmpthese(-5, {
...,
new_hash => sub {
my %h = map {$_,1} @in_middle;
my $count = 0;
foreach ( @hits ) { $count++ if exists $h{$_} }
$count;
},
old_hash => sub {
my $count = 0;
foreach ( @hits ) { $count++ if exists $old_hash{$_} }
$count;
},
control_hash => sub {
my $count = 0;
foreach ( @hits ) { $count++ }
$count;
},
}
);
Вот сюжет.Цвета немного сложно различить.Самая нижняя строка - это случай, когда вам нужно создать хеш в любое время, когда вы захотите найти его.Это довольно бедно.Две верхние (зеленые) строки - это элемент управления для хэша (на самом деле никакого хэша там нет) и поиска существующего хеша.Это лог / сюжет журнала;эти два случая быстрее, чем даже умный контроль соответствия (который просто вызывает подпрограмму).

Есть еще несколько вещей, на которые стоит обратить внимание. Строки для «случайного» случая немного отличаются. Это понятно, потому что каждый бенчмарк (то есть один раз на масштабирование массива) случайным образом размещает элементы попадания в массиве-кандидате. Некоторые прогоны помещают их немного раньше, а некоторые чуть позже, но, поскольку я создаю массив @random только один раз за прогон всей программы, они немного перемещаются. Это означает, что неровности на линии незначительны. Если я попробую все позиции и усредню, я ожидаю, что эта «случайная» линия будет такой же, как и «средняя» линия.
Теперь, глядя на эти результаты, я бы сказал, что в худшем случае умное сопоставление выполняется намного быстрее, чем в худшем. В этом есть смысл. Чтобы создать хеш, я должен посетить каждый элемент массива и также сделать хеш, который много копирует. С умным совпадением копирование невозможно.
Вот еще один случай, который я не буду рассматривать. Когда хэш становится лучше, чем умный матч? То есть, когда накладные расходы на создание хэша распределяются достаточно по повторным поискам, чтобы хеш был лучшим выбором?