Разделяй и властвуй!
Если вы все-таки решите пойти по этому пути "внутри дома".Ваша конструкция должна иметь масштабируемость начиная с первого дня.
Это один из редких случаев, когда задачу можно разбить и выполнить параллельно .
Если у вас естьДокументы 10K, даже если вы создали и развернули 10x (сканеры + серверы + пользовательское приложение), что означало бы, что каждая система должна будет обрабатывать только около 1k документов каждый.
Задача состоит в том, чтобы сделать ее дешевой и надежной. «решение под ключ» .
Возможно, прикладная сторона является более простым элементом, если у вас есть хорошая автоматизированная система обновлений, разработанная с самого начала, вы можете просто добавить оборудование по мере необходимости.расширяйте свою «ферму / кластер».
, сохраняя свой дизайн модульным (т. е. используйте дешевое аппаратное оборудование), позволит вам комбинировать и подбирать оборудование / заменять по требованию, не влияя на ежедневную пропускную способность.
Сначала попытайтесь найти решение «под ключ», способное легко поддерживать 1000 документов.Затем, как только это сработает, увеличьте масштаб!
Удачи!
Редактировать 1:
Хорошо, вот более подробный ответ на каждый конкретный вопрос, который вы подняли:
Какие системы используются для сканирования чеков ипочта, и они очень хорошо читают грязную почерку?
Одна из таких систем, используемая компанией почтовой / почтовой доставки "TNT" здесь, в Великобритании, предоставлена нидерландской компанией 'Prime Vision' и их HYCR Двигатель.
Я настоятельно рекомендую вам связаться с ними.Распознавание рукописных данных никогда не будет очень точным, OCR на печатных символах может иногда достигать точности 99%.
Кто-нибудь имел опыт создания базы данных с кучей документов с возможностью поиска OCR?Какие инструменты мне следует использовать для решения моей проблемы?
Не специально для документов OCR, но для одного из наших клиентов я создаю и поддерживаю очень большую и сложную систему EDMS, которая содержит очень большое разнообразие документов.форматы.Он доступен для поиска несколькими различными способами с помощью сложного набора доступа к данным.
Что касается рекомендаций, я бы сказал несколько вещей, которые следует иметь в виду:
- Храните документы в файле и располагайте ссылкой в базе данных
- Храните документ непосредственно в базе данных как данные BLOB.
Каждый подход имеет свой набор «за» и «против».Мы решили пойти по первому маршруту.С точки зрения возможности поиска, как только у вас есть метаданные фактических документов.Это просто вопрос создания пользовательских поисковых запросов.Я построил поиск на основе рейтинга, он просто дал более высокий рейтинг тем, которые соответствовали большему количеству токенов.Конечно, вы можете использовать полочные инструменты поиска (библиотеки), такие как Lucene Project .
Можете ли вы порекомендовать лучшие библиотеки OCR?
да:
Как программист, что бы вы сделалиЧтобы решить эту проблему?
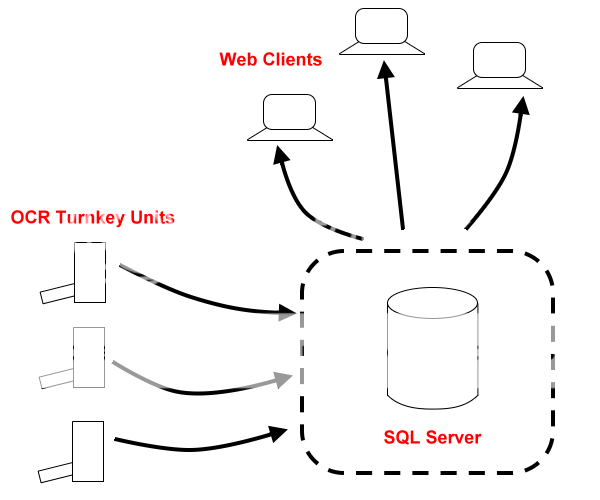
Как описано выше, см. диаграмму ниже.Сердцем системы будет ваша база данных, вам нужно будет иметь передний слой презентации, чтобы клиенты (могли быть веб-приложения) могли искать документы в вашей базе данных.Вторая часть будет «серверами» OCR на основе «под ключ».
Для этих 'Серверов OCR' я бы просто реализовал 'drop folder' (которая могла бы быть папкой FTP).Ваше пользовательское приложение может просто отслеживать эту папку (класс Folder Watcher в .NET).Файлы могут быть отправлены непосредственно в эту папку FTP.
Ваше пользовательское приложение OCR будет просто отслеживать удаленную папку и после получения нового файла сканировать его, генерировать метаданные и затем перемещать его в «отсканированную» папку ».Те, которые являются дубликатами или не смогли отсканировать, могут быть перемещены в их собственную «папку с ошибками».
Приложение OCR затем подключится к вашей основной базе данных и выполнит несколько вставок или обновлений (это перемещает METADATA в основную базу данных).
В фоновом режиме вы можете синхронизировать «Отсканированную папку» с зеркальной папкой на вашем сервере базы данных (ваш SQL-сервер, как показано на схеме) (это физически)копирует ваш отсканированный и OCR-документ на главный сервер, где связанные записи уже были перемещены.)
В любом случае, именно так я бы решил эту проблему.Я лично реализовал одно или несколько из этих решений, поэтому я уверен, что это сработает и будет масштабируемым.
Масштабируемость является ключевой здесь.По этой причине вы можете захотеть взглянуть на альтернативную базу данных, отличную от традиционной.
Я бы порекомендовал вам хотя бы подумать о базе данных типа NoSQL для этого проекта.:
Например
Без стыдного штекера:
Конечно, за 40 000 фунтов я бы построил и настроил все решениедля вас (включая аппаратное обеспечение)!
:) Я шучу ТАК пользователей!
РЕДАКТИРОВАТЬ 2:
Обратите внимание на упоминание META DATA ,под этим я подразумеваю то же самое, на что ссылались другие.Тот факт, что вы должны сохранить оригинальную отсканированную копию в виде файла изображения вместе с метаданными распознавания текста (чтобы он позволял осуществлять поиск по тексту).
Я подумал, что проясню это вВ этом случае предполагалось, что это не было частью моего решения.