Вычисление k-core графа путем итеративного сокращения вершин достаточно просто. Однако для моего приложения я хотел бы иметь возможность добавлять вершины в начальный граф и получать обновленное ядро, не пересчитывая все k-ядро с нуля. Есть ли надежный алгоритм, который может использовать в своих интересах работу, проделанную на предыдущих итерациях?
Для любопытных k-ядро используется в качестве этапа предварительной обработки в алгоритме поиска клики. Любые клики размером 5 гарантированно являются частью 4-го ядра графа. В моем наборе данных, 4-ядерное ядро намного меньше, чем весь граф, поэтому его можно было бы перебором. Постепенное добавление вершин позволяет алгоритму работать с минимально возможным набором данных. Мой набор вершин бесконечен и упорядочен (простые числа), но я забочусь только о клике с наименьшим номером.
Edit:
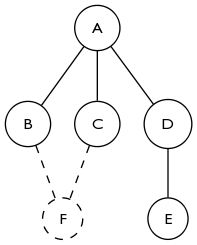
Если подумать еще об этом, основываясь на ответе акаппы, обнаружение создания цикла действительно важно. На приведенном ниже графике 2-ядро пусто до добавления F. Добавление F не меняет степень A, но все равно добавляет A к 2-ядру. Это легко расширить, чтобы увидеть, как закрытие цикла любого размера приведет к тому, что все вершины одновременно присоединятся к 2-ядерному.
Добавление вершины может повлиять на остроту вершин на произвольном расстоянии, но, возможно, это слишком сфокусировано на поведении в худшем случае.