Вопрос
Насколько меньше в автоэнкодере LSTM уменьшаются мои входные данные (59 функций) в скрытом векторе, который обычно находится посередине между кодером и декодером?
Почему автор увеличил номер функции с 5 до 16 в середине этапа кодирования. Этот вопрос более подробно описан ниже после рисунка структуры автоэнкодера LSTM.
Мои вопросы основаны на статье Автокодер LSTM для классификации экстремальных редких событий в Керасе . Вы можете взглянуть на коды из этого репозитория github . Пожалуйста, обратитесь к этим ресурсам, чтобы лучше узнать мои вопросы.
Подробности вопроса
- Моя модель автоэнкодера выглядит следующим образом:
lstm_autoencoder = Sequential()
# Encoder
lstm_autoencoder.add(LSTM(timesteps, activation='relu', input_shape=(timesteps, n_features), return_sequences=True))
lstm_autoencoder.add(LSTM(16, activation='relu', return_sequences=True))
lstm_autoencoder.add(LSTM(1, activation='relu'))
lstm_autoencoder.add(RepeatVector(timesteps))
# Decoder
lstm_autoencoder.add(LSTM(timesteps, activation='relu', return_sequences=True))
lstm_autoencoder.add(LSTM(16, activation='relu', return_sequences=True))
lstm_autoencoder.add(TimeDistributed(Dense(n_features)))
lstm_autoencoder.summary()
Форма входных данных X_train_y0_scaled.shape = (11692,5,59). Это значит, что у нас 11692 партии. Каждая партия состоит из 5 строк и 59 столбцов, и поскольку данные являются данными временного ряда, это означает, что для каждого из 5 дней собираются 59 объектов.
Краткое описание модели автоэнкодера выглядит следующим образом:
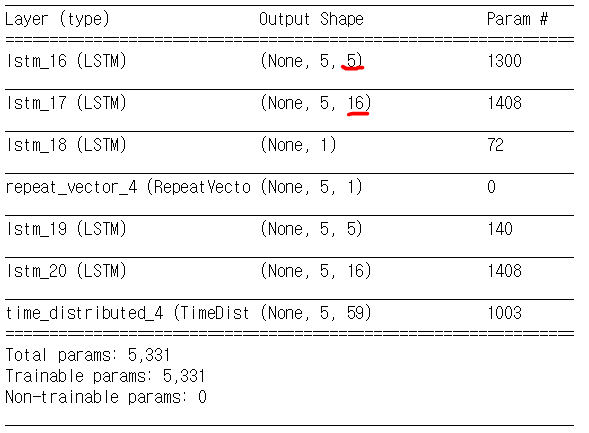
- Дополнительный вопрос: я не могу понять, почему автор этого кода увеличил номер объекта с 5 (в слое lstm_16) до 16 (в слое lstm_17).
- Исходный номер объекта равен 59, поэтому в первом слое номер объекта был уменьшен с 59 до 5. Но после этого уменьшения размера, почему кто-то захочет увеличить размер на этапе кодирования?!
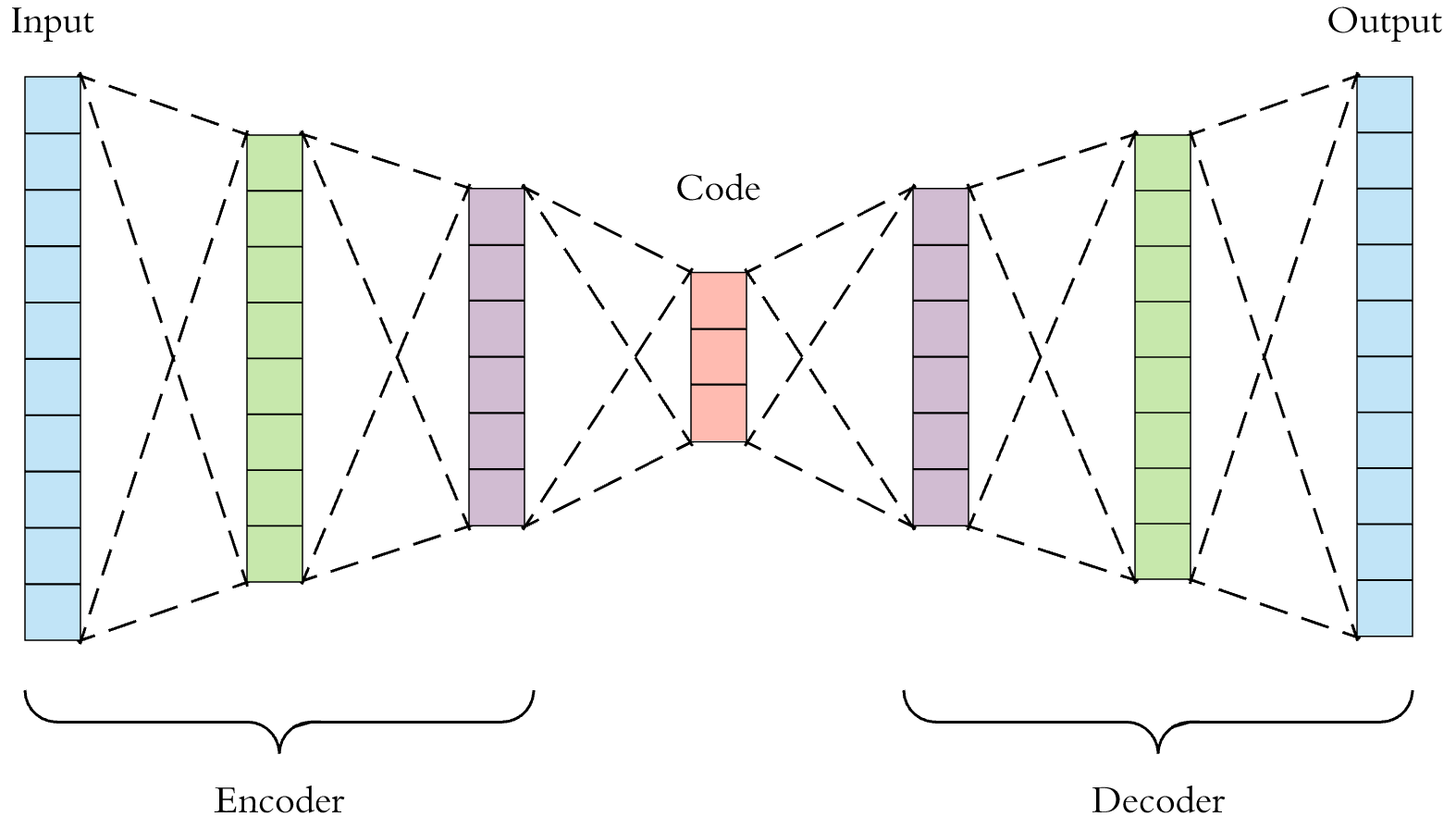
Легко видеть, насколько меньше форма входных данных уменьшается в скрытом векторе, если это полностью подключенный автоэнкодер. Например, на рисунке ниже входные данные длиной 10 узлов сокращаются до скрытого вектора длиной 3 узла.
Однако в автоэнкодере LSTM мне не ясно, как долго сокращается вектор 59 длинных объектов. The layer lstm_18 имеет длину всего 1 узел, тогда как repeat vector имеет длину (5,1). Означает ли это, что длинный вектор из 59 элементов уменьшен до длинного вектора из 1 узла?