Я борюсь с тем, как лучше структурировать категориальные данные, которые являются беспорядочными и поступают из набора данных , который мне нужно очистить.
Схема кодирования
Я анализирую данные экзамена по университетскому научному курсу. Мы смотрим на шаблоны в
ответы студентов, и мы разработали схему кодирования для представления видов вещей
студенты делают в своих ответах. Подмножество схемы кодирования показано ниже.
<а
href = "http://picasaweb.google.com/lh/photo/0tut3kR-JFoB0cP_0uFBZg?feat=embedwebsite" rel =" nofollow noreferrer "> 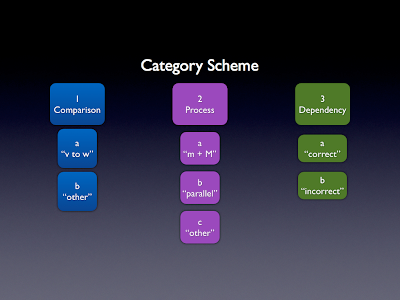
Обратите внимание, что внутри каждого основного кода (1, 2, 3) находятся вложенные неуникальные субкоды (a, b, ...).
Как выглядят необработанные данные
Я создал анонимное необработанное подмножество моих фактических данных, которые вы можете просмотреть здесь .
Часть моей проблемы в том, что те, кто закодировал данные, заметили, что некоторые студенты
несколько моделей. Решение кодеров состояло в том, чтобы создать достаточно столбцов (reason1, reason2,
...) чтобы держать студентов с несколькими образцами. Это становится важным, потому что порядок
(reason1, reason2) произвольно - два студента (как студент 41 и студент 42 в моем
набор данных ) которые правильно применили «зависимость», должны регистрироваться в анализе независимо от того,
отображается ли 3a в столбце reason или в столбце reason2.
Как лучше структурировать данные об учениках?
Часть моей проблемы заключается в том, что в необработанных данных не все учащиеся отображают одно и то же
шаблоны или одинаковое их количество в одинаковом порядке. Некоторые студенты могут сделать только один
вещь, другие могут сделать несколько. Таким образом, абстрактное представление примеров студентов может
выглядеть так:
<а
href = "http://picasaweb.google.com/lh/photo/sQgGKgseA07Z_lKxRe4fkQ?feat=embedwebsite" rel =" nofollow noreferrer "> 
Обратите внимание, что в приведенном выше примере оба student002 и student003 кодируются как "1b", хотя я намеренно показал порядок как отличный, чтобы отразить реальность моих данных .
Мои (практические) вопросы
- Должен ли я объединить
reason1, reason2, ... в один столбец?
- Как я могу (пере) кодировать
reason s в R, чтобы отразить множественность для некоторых студентов?
Спасибо
Я понимаю, что этот вопрос касается как концептуализации данных, так и специфических особенностей R, но я подумал, что было бы целесообразно задать этот вопрос здесь. Если вы считаете, что мне неуместно задавать вопрос, сообщите мне об этом в комментариях, и stackoverflow автоматически заполнит мой почтовый ящик смайликами печального лица. Если я не был достаточно конкретен, пожалуйста, дайте мне знать, и я сделаю все возможное, чтобы быть более ясным.