Я не уверен, с каким типом данных вы имеете дело, но вот метод, который я использовал для обработки речевых данных, который может помочь вам найти локальные максимумы. Он использует три функции из панели инструментов обработки сигналов: ГИЛЬБЕРТ , БАБОЧКА и FILTFILT .
data = (...the waveform of noisy data...);
Fs = (...the sampling rate of the data...);
[b,a] = butter(5,20/(Fs/2),'low'); % Create a low-pass butterworth filter;
% adjust the values as needed.
smoothData = filtfilt(b,a,abs(hilbert(data))); % Apply a hilbert transform
% and filter the data.
Затем вы выполните поиск максимума для smoothData . Использование HILBERT сначала создает положительный конверт в данных, затем FILTFILT использует коэффициенты фильтра от BUTTER для низкочастотной фильтрации конверта данных.
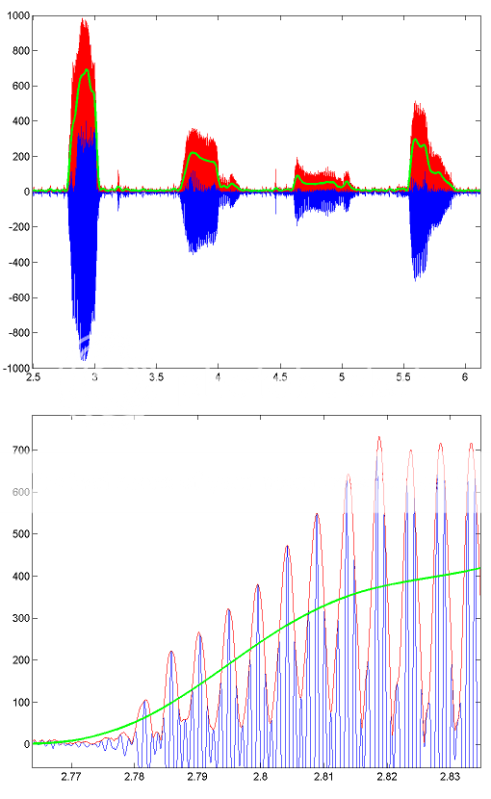
В качестве примера того, как работает эта обработка, вот несколько изображений, показывающих результаты для сегмента записанной речи. Синяя линия - это исходный речевой сигнал, красная линия - конверт (полученный с использованием HILBERT), а зеленая линия - результат фильтрации нижних частот. Нижний рисунок увеличен в версии первого.
ЧТО-ТО СЛУЧАЙНО ПОПРОБОВАТЬ:
Сначала это была случайная идея ... вы можете попытаться повторить процесс, найдя максимумы максим:
index = find(diff(sign(diff([0; x(:); 0]))) < 0);
maxIndex = index(find(diff(sign(diff([0; x(index); 0]))) < 0));
Однако, в зависимости от отношения сигнал / шум, было бы неясно, сколько раз это нужно будет повторить, чтобы получить интересующие вас локальные максимумы. Это просто случайная опция без фильтрации. =) * * Один тысяча двадцать-шесть
НАЙТИ МАКСИМА:
На всякий случай вам может понравиться еще один алгоритм нахождения максимума в одну строку, который я видел (в дополнение к указанному вами):
index = find((x > [x(1) x(1:(end-1))]) & (x >= [x(2:end) x(end)]));