Я построил простой детектор слов CNN, который точно способен предсказать данное слово при использовании 1-секундного .wav в качестве ввода. Как представляется, стандарт, я использую MFCC аудиофайлов в качестве входных данных для CNN.
Однако моя цель состоит в том, чтобы иметь возможность применить это к более длинным аудиофайлам с произносимыми несколькими словами, и чтобы модель могла предсказать, произойдет ли и когда произойдет данное слово. Я искал в Интернете, как лучше всего подходить, но, кажется, бьется в стену, и я искренне извиняюсь, если бы ответ был легко найден через Google.
Моя первая мысль - разрезать аудиофайл на несколько окон продолжительностью 1 секунда, которые пересекаются друг с другом -
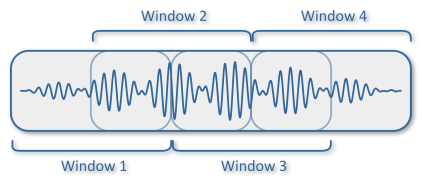
, а затем преобразовать каждое окно в MFCC и использовать их в качестве входных данных для прогнозирования модели.
Моя вторая мысль состояла бы в том, чтобы вместо этого использовать обнаружение начала в попытках изолировать каждое слово, добавить отступ, если слово было <1 секунда, и затем передать их в качестве входных данных для прогнозирования модели. </p>
Я здесь далеко? Любые ссылки или рекомендации будут с благодарностью. Спасибо.