для домашнего задания я должен нанести частоту слов текста и сравнить ее с оптимальным распределением zipf.
Кажется, что построение подсчитанных частот слов текста в соответствии с их рангом на графике журнала отлично работает.
Но я спорю с расчетом оптимального распределения zipf. Результат должен выглядеть примерно так:
Я не понимаю, как будет выглядеть уравнение для вычисления прямой линии zipf.
На странице немецкого википедии закона zipf я нашел уравнение, которое, кажется, работает

но источники не цитируются, поэтому я не понимаю, откуда взялась константа 1.78.
#tokenizes the file
tokens = word_tokenize(raw)
tokensNLTK = Text(tokens)
#calculates the FreqDist of all words - all words in lower case
freq_list = FreqDist([w.lower() for w in tokensNLTK]).most_common()
#Data for X- and Y-Axis plot
values=[]
for item in (freq_list):
value = (list(item)[1]) / len([w.lower() for w in tokensNLTK])
values.append(value)
#graph of counted frequencies gets plotted
plt.yscale('log')
plt.xscale('log')
plt.plot(np.array(list(range(1, (len(values)+1)))), np.array(values))
#graph of optimal zipf distribution is plotted
optimal_zipf = 1/(np.array(list(range(1, (len(values)+1))))* np.log(1.78*len(values)))###1.78
plt.plot(np.array(list(range(1, (len(values)+1)))), optimal_zipf)
plt.show()
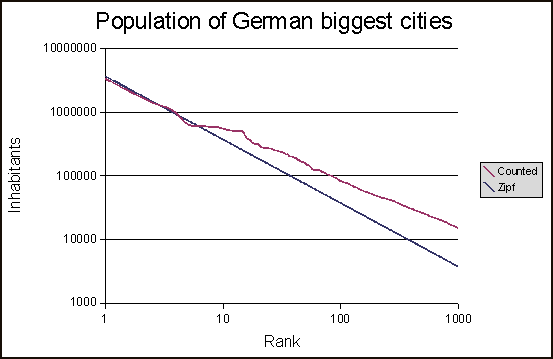
Мои результаты с этим скриптом выглядят так:

но я просто не уверен, правильно ли рассчитано оптимальное zipf распределение. Если так, то не должно ли оптимальное распределение zipf пересечь ось X в одной точке?
РЕДАКТИРОВАТЬ: если это помогает, мой текст имеет 2440400 токенов и 27491 типов