Я пытаюсь настроить практическую демонстрацию Microservice для нескольких простых внутренних систем, которые занимаются управлением заказами в моей компании, однако я пытаюсь понять, что согласованность данных между Microservices, когда в масштабе.
Я определил простой сценарий для микросервисов - текущее приложение, которое у нас в игре, принимает заказы по мере их обработки на нашем веб-сайте и обновляет «Кредит учетной записи» для клиентов - в основном те непогашенные деньги, которые они могут потратить с нами перед своей учетной записью. нуждается в пересмотре.
Я попытался разбить это ОЧЕНЬ простое требование на несколько микросервисов. Они определены ниже:
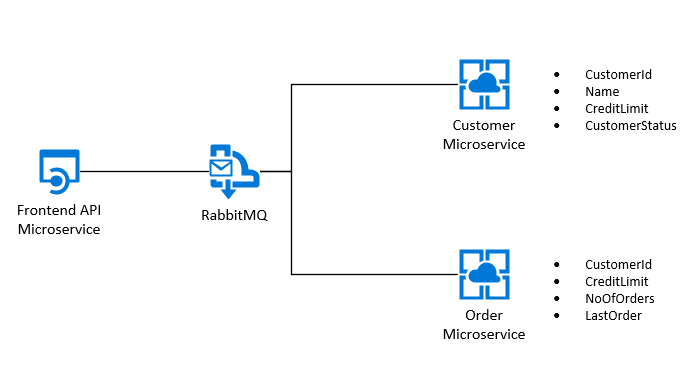
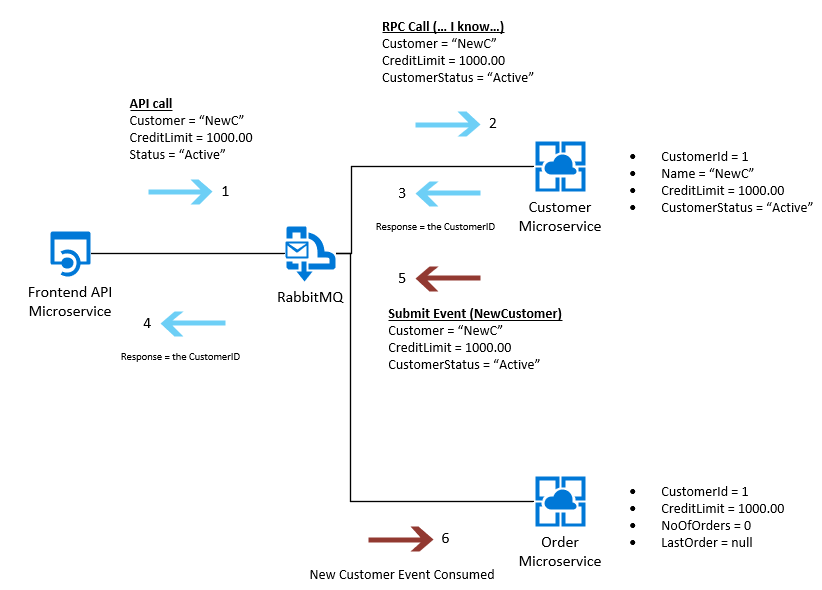
API предоставляет различные уровни функциональности - он позволяет нам создавать нового клиента, и это вызывает следующее:
С помощью SQL мы можем выполнять некоторые оптимистичные запросы при работе с базой данных, чтобы попытаться гарантировать, что при одновременной обработке двух заказов путем масштабирования микросервисов (например, два экземпляра микросервиса заказов, где каждый микросервис, но не каждый экземпляр микросервиса имеет свою собственную базу данных).
Например, мы можем сделать следующее и предположить, что SQL будет управлять блокировкой, что означает, что число должно заканчиваться на правильном числе, когда два заказа обрабатываются одновременно:
UPDATE [orderms].[customers] SET CreditLimit = CreditLimit - 100, NoOfOrders = NoOfOrders + 1 WHERE CustomerId = 1
С учетом вышеизложенного, если кредит был равен 1000, и 2 заказа по 100 обрабатываются, и каждый заказ распределяется по отдельному экземпляру микросервиса «Заказ», мы должны предполагать, что правильные цифры будут присутствовать в таблица клиентов в микросервисе заказа (блокировка на основе запросов MSSQL должна позаботиться об этом автоматически).
Проблема возникает тогда, когда мы пытаемся интегрировать их обратно в микросервис клиента. У нас будет два сообщения от каждого экземпляра микросервиса заказа, передаваемого как событие, например, как показано ниже:
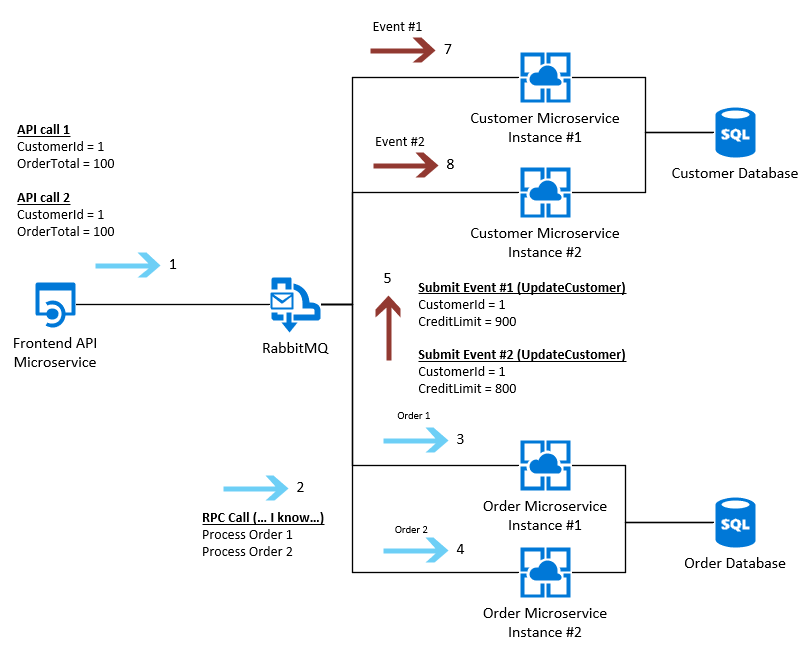
Учитывая вышеизложенное - вероятно, мы будем следовать схеме обновления таблицы SQL «Клиент» согласно следующему (это два запроса):
UPDATE [customerms].[customers] SET CreditLimit = 900.00 WHERE CustomerId = 1
UPDATE [customerms].[customers] SET CreditLimit = 800.00 WHERE CustomerId = 1
Однако - в зависимости от скорости, с которой работают эти "Микросервисы" Клиента, Экземпляр # 1 может в настоящий момент создавать несколько новых Клиентов, и поэтому может обрабатывать этот запрос медленнее, чем Экземпляр № 2, что означает запросы SQL будет выполнено не по порядку, и поэтому у нас останется база данных «Заказ» с CreditLimit 800 (правильно) и клиентская микросервис с CreditLimit 900 (неправильно).
В монолитном приложении мы обычно добавляем элемент блокировки (или, возможно, Mutex), если это действительно необходимо, в противном случае мы будем полагаться на блокировку SQL согласно функциональности в микросервисе Order, однако, поскольку это распределенный процесс, ни один из этих более старых методов не будет применяться.
Есть совет? Кажется, я не вижу, как это проходит?